Stratego is a popular board game that involves strategy and deception. Players take turns moving their pieces, with the goal of capturing their opponent’s flag or trapping their opponent’s pieces. It is a challenging game that requires players to think carefully about their moves and outmaneuver their opponent.
DeepMind, a company owned by Alphabet, has developed an AI that can play the board game Stratego. Stratego is a game of imperfect information, meaning that players do not have full knowledge of the game state at any given time. This makes it a difficult game for AI to play, as it must make decisions without complete information.
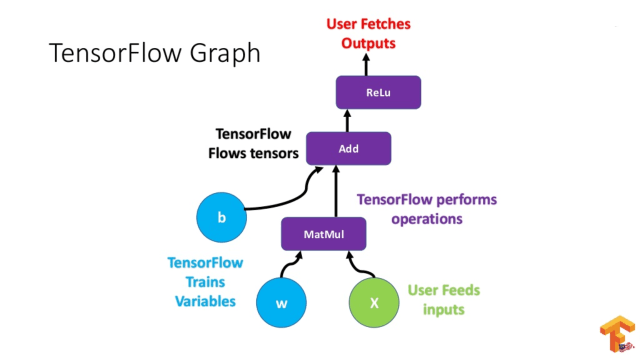
The DeepMind AI uses a combination of neural networks and Monte Carlo Tree Search (MCTS) algorithms to play the game. The neural networks are trained using supervised learning, in which the AI is fed a large number of example game states and their corresponding optimal moves. The MCTS algorithms then use this knowledge to make decisions during gameplay.
The AI was able to defeat a strong human player in a series of games, showing that it is capable of making strategic decisions and adapting to its opponent’s moves. The researchers believe that the AI’s ability to handle imperfect information could have applications in other domains, such as cybersecurity and finance.
The development of this AI is an important step in the field of game AI, as it shows that AI can be successful in games with incomplete information. This has implications for other areas of AI research, as many real-world problems also involve incomplete information.